hadoop的安装和使用
环境配置
- UbuntuKylin 16.04.7
- JDK 1.8.0
下面的操作其实就是安装虚拟机和配置环境
本文是写给Linux小白和为了完成作业和修学分的大学生的
熟悉Linux的人自己挑关键部分看就行
安装虚拟机
本文使用VMware安装,你也可以使用virtualbox,WSL等环境构建
1. 新建虚拟机,选择镜像文件
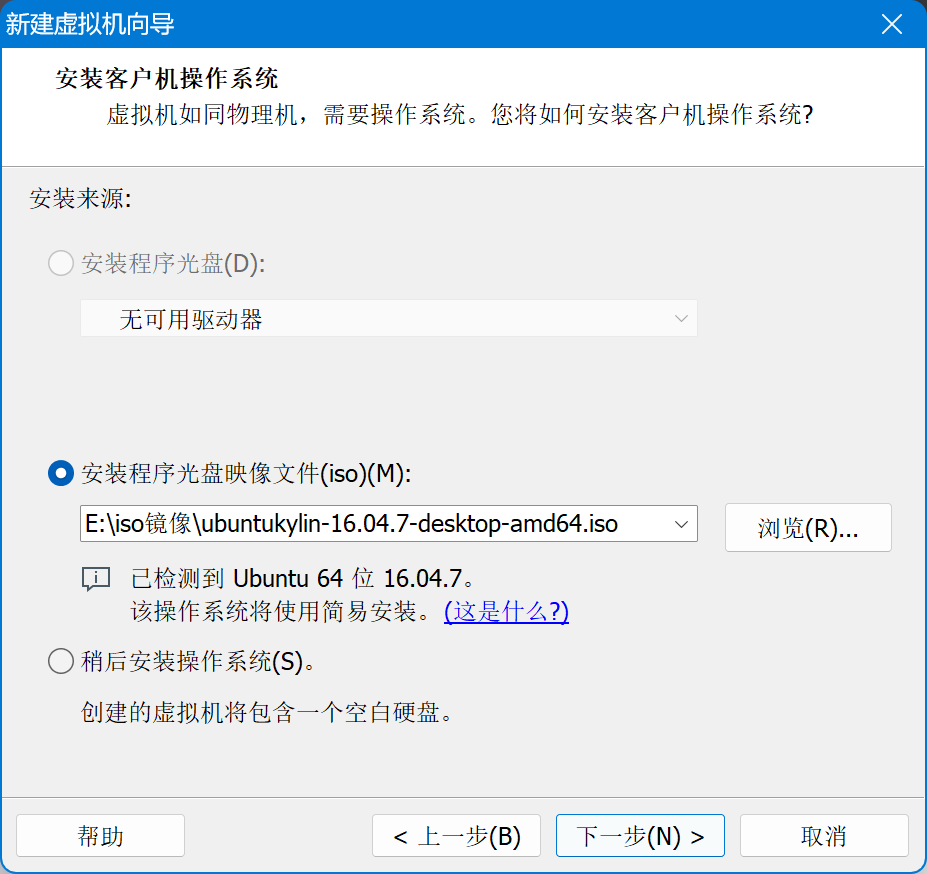
磁盘空间建议设置大一点,用户名可以任意,或者直接设置为 hadoop,其他配置按需调整,接下来一路完成即可
等待安装完毕进入系统
注意,安装时建议不要勾选更新和下载软件,默认源很慢
2. 更换镜像源&&更新软件包
通过命令更换ubuntu镜像可以参考我这篇文章
部分公共服务镜像
对新手来说,换源还是建议通过ubuntu内置的镜像源选择器
位置在:右上角找到设置-系统设置(System Settings)

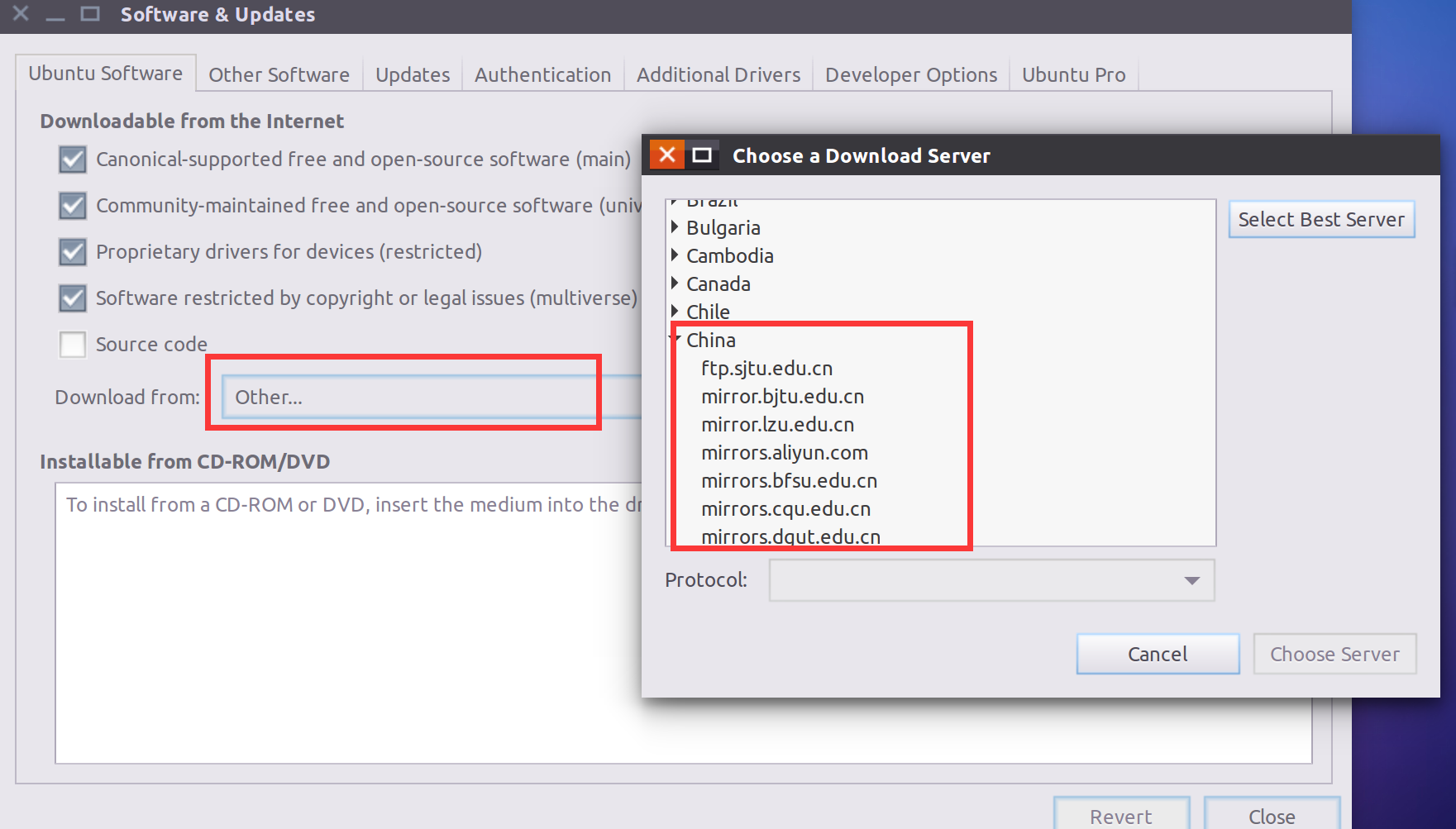
Download from点击Other,往上翻找到China,选择一个镜像即可
个人建议选择中科大
mirrors.ustc.edu.cn或者清华大学tsinghua,不建议使用阿里云aliyun,部分地区速度比不换还慢
后会弹出一个窗口提示软件列表已过时,我们点击关闭
回到桌面,右键任意空白处选择Open Terminal进入终端输入,并输入之前设置的密码
1 | sudo apt update && apt upgrade -y |
等待命令执行完成
ps: 期间如果报错无法连接到ubuntukylin.com, 或者卡在这里
就按Ctrl+C结束当前命令后,输入以下命令删除UbuntuKylin的软件源后重新执行上面的命令
1 | sudo rm -rf /etc/apt/sources.list.d/ubuntukylin.list |
3. 新建hadoop用户
若第一步建立的用户就是hadoop,直接跳过即可
1 | sudo useradd -m hadoop -s /bin/bash |
然后注销,以hadoop用户重新登录
4. 开启虚拟机SSH服务
开启SSH后,我们可以直接在宿主机通过SSH客户端连接到虚拟机的终端,以实现宿主机直接复制粘贴到虚拟机内
同时也可以通过SFTP协议实现宿主机和虚拟机文件互相传输
如果使用WSL,这一步直接省略即可,虚拟机安装的建议开启SSH服务
虚拟机内部和宿主机的剪贴板共享容易出问题
同样打开右键终端输入,根据提示输入y确认
1 | sudo apt-get install openssh-server |
安装完成后输入下面的命令测试SSH服务是否成功安装
1 | ssh localhost |
如出现类似下图的提示,说明安装成功
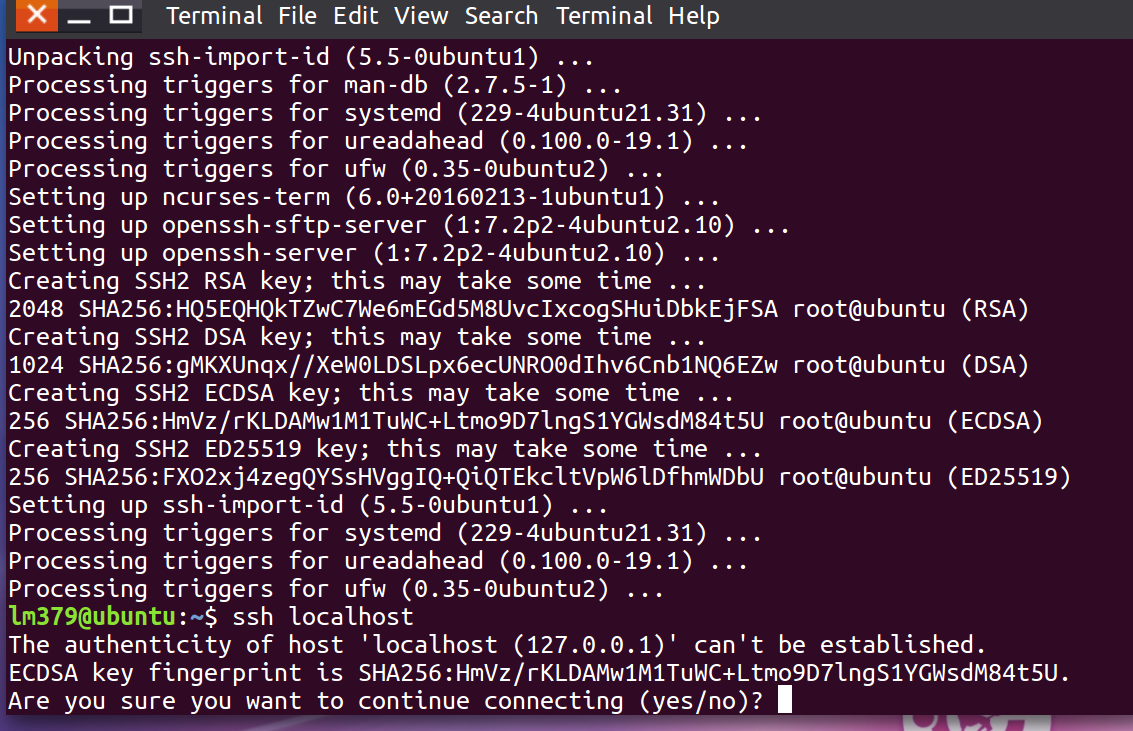
然后按Ctrl+C取消连接
宿主机通过SSH工具连接到虚拟机
常用的SSH工具有XSHELL MobaXterm FinalShell PuTTY 等等
Windows内置了SSH的命令行客户端,可以直接调出CMD,PowerShell或者Windows Terminal通过命令连接,VMware内置的SSH连接就是调用Windows自带的终端实现的
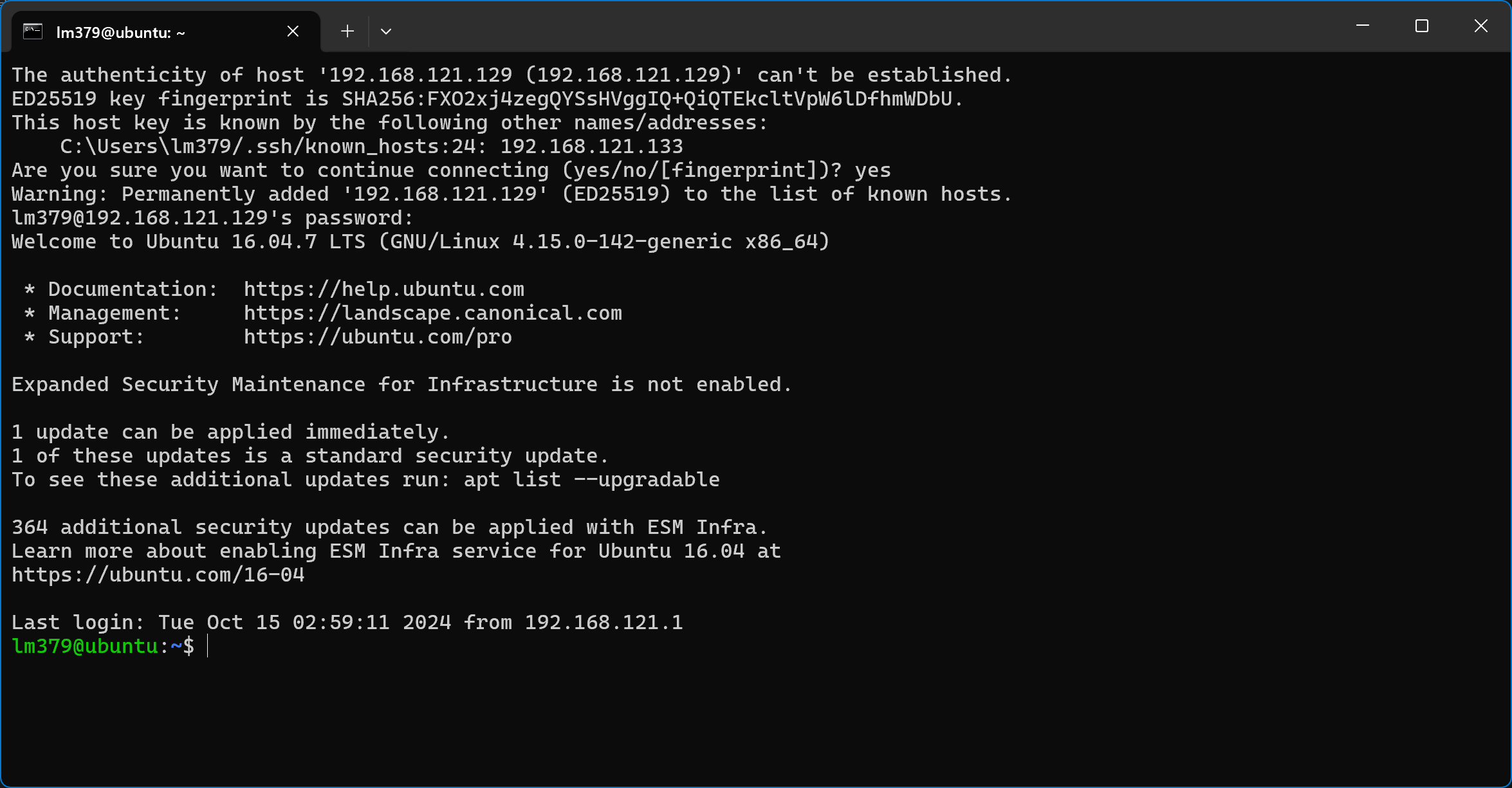
第一次连接需要先输入yes,然后输入当前用户的密码即可连接
直接在命令行内输入
ssh username@ip也能达到同样的效果
那么问题来了,既然内置的工具已经可以实现命令交互,为什么还需要第三方SSH工具呢?
上面的截图可以看到,Windows Terminal基本仅仅支持命令行,而很多SSH工具内置了SFTP传输文件,保存连接配置,设置自定义密钥,有些甚至还支持查看远程主机的系统资源信息,下面我以个人比较习惯的XShell为例
XShell这个软件功能非常强大,虽然软件收费,但是对于个人和学校是免费使用的
可以在家庭/学校免费 - NetSarang Website (xshell.com)直接下载XShell和XFTP这两个组件
XShell的SFTP基于XFTP实现,所以都要下载
然后输入用户名和邮箱即可免费注册使用
在连接之前需要知道虚拟机网络连接方式和虚拟机的IP地址
我这里虚拟机网络为NAT模式,后面也以NAT方式为例
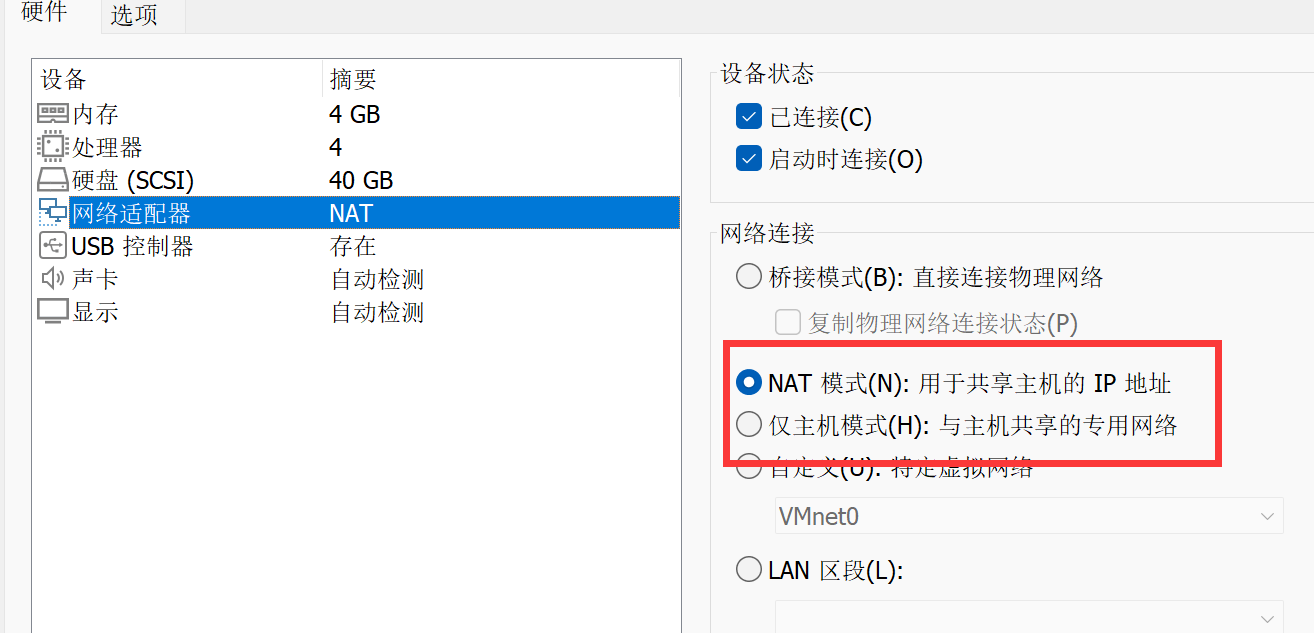
进入虚拟机,点击网络,找到连接信息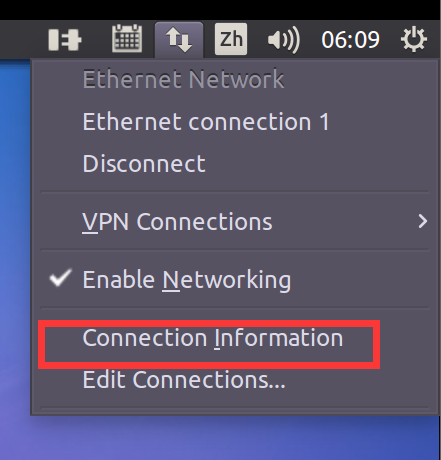
图中的位置就是虚拟机的IP地址,比如我的就是 192.168.121.129
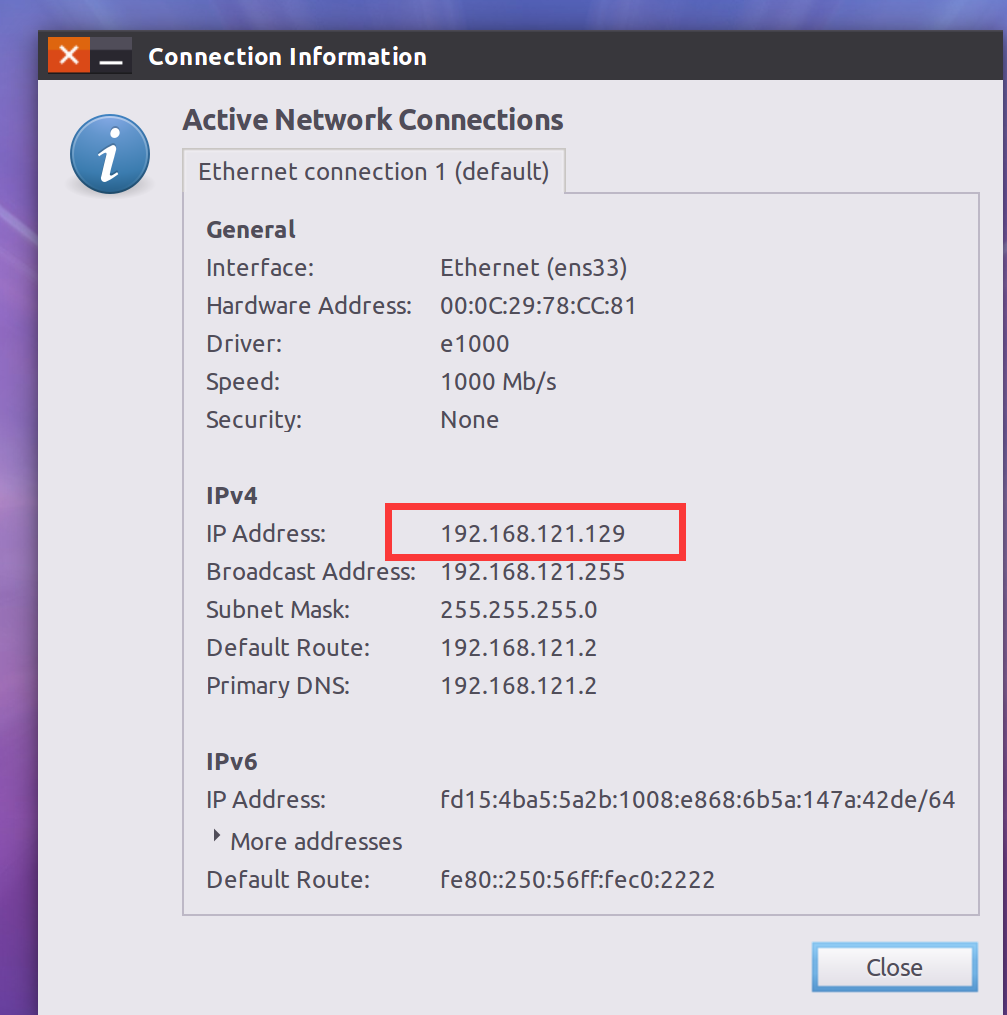
然后在VMware中点击 编辑 - 虚拟网络编辑器,并以管理员重新打开
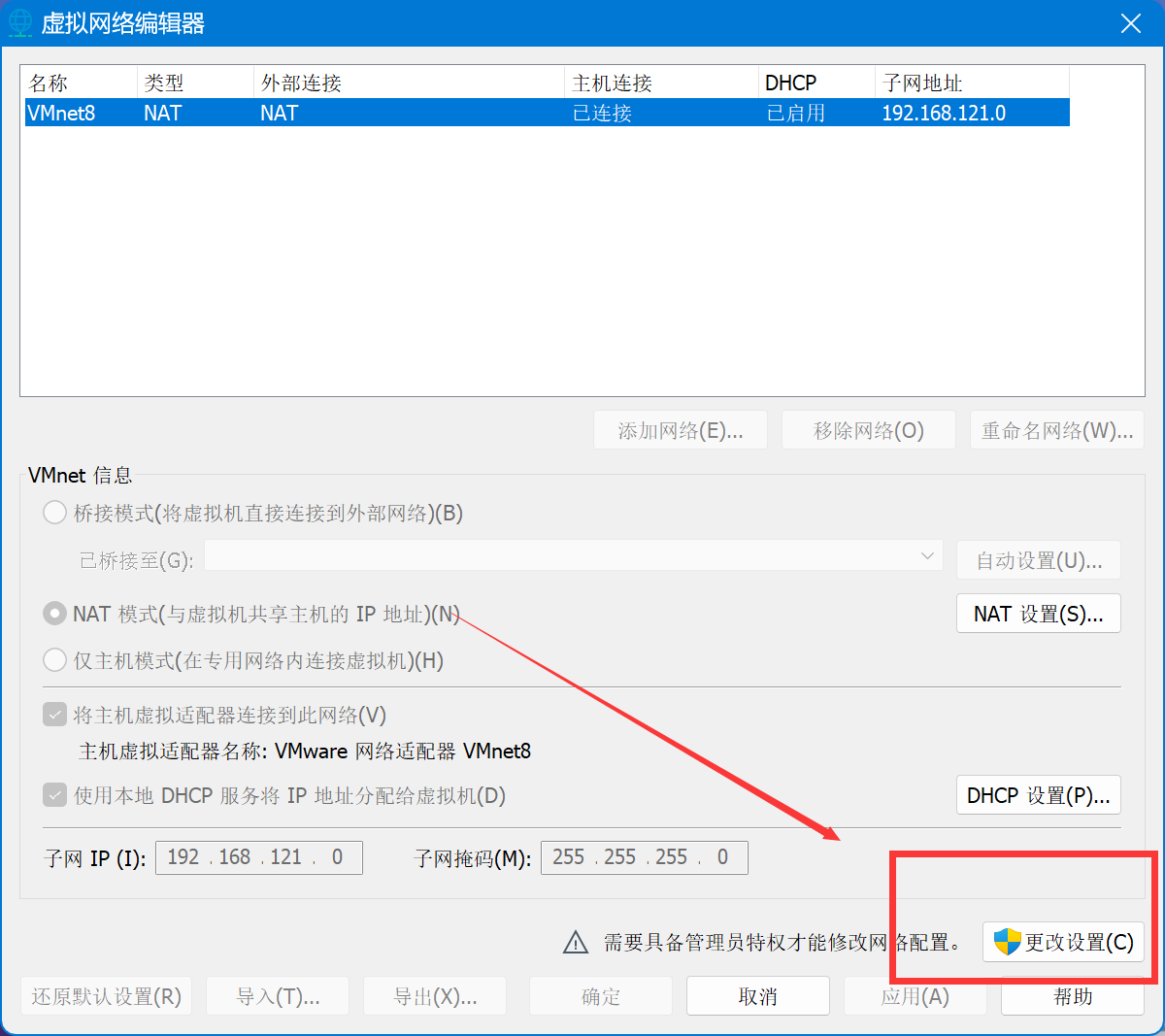
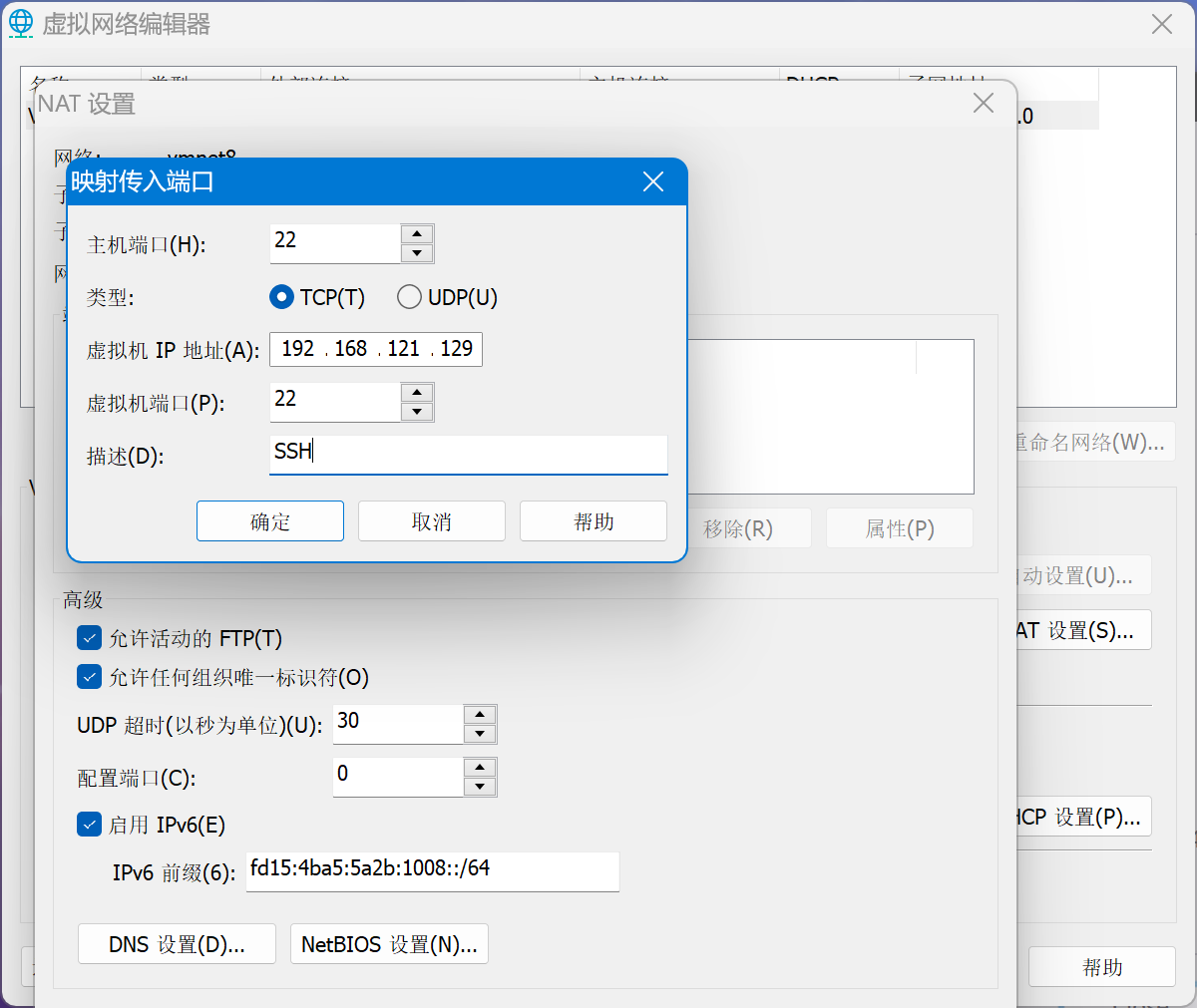
然后在上面选择和虚拟机相同网段的虚拟网卡后,点击NAT设置,按下图的方式填写端口转发
回到XShell,点击新增,在主机处输入虚拟机IP地址
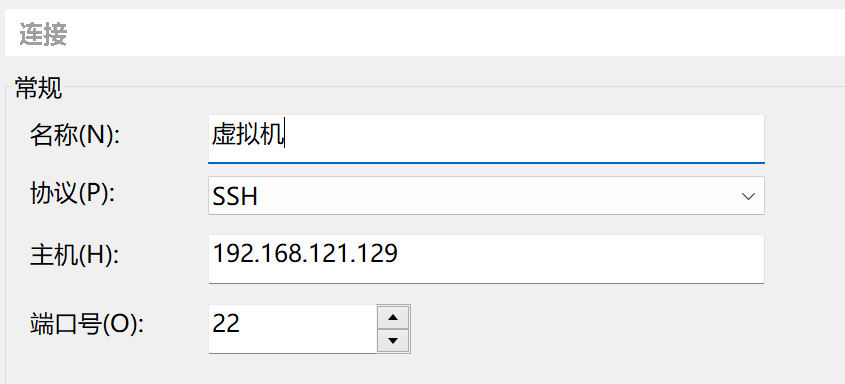
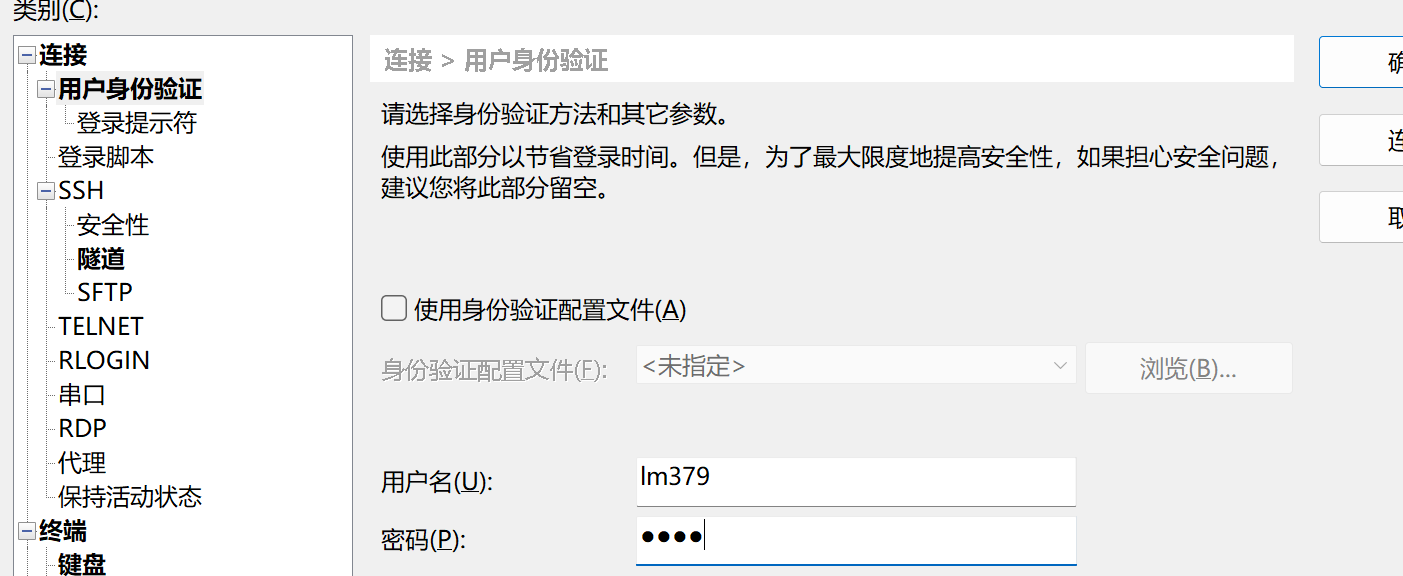
然后点击左侧用户身份验证,输入虚拟机的用户名和密码点击连接即可
第一次连接需要接受主机密钥
然后就进到了SSH终端,可以和
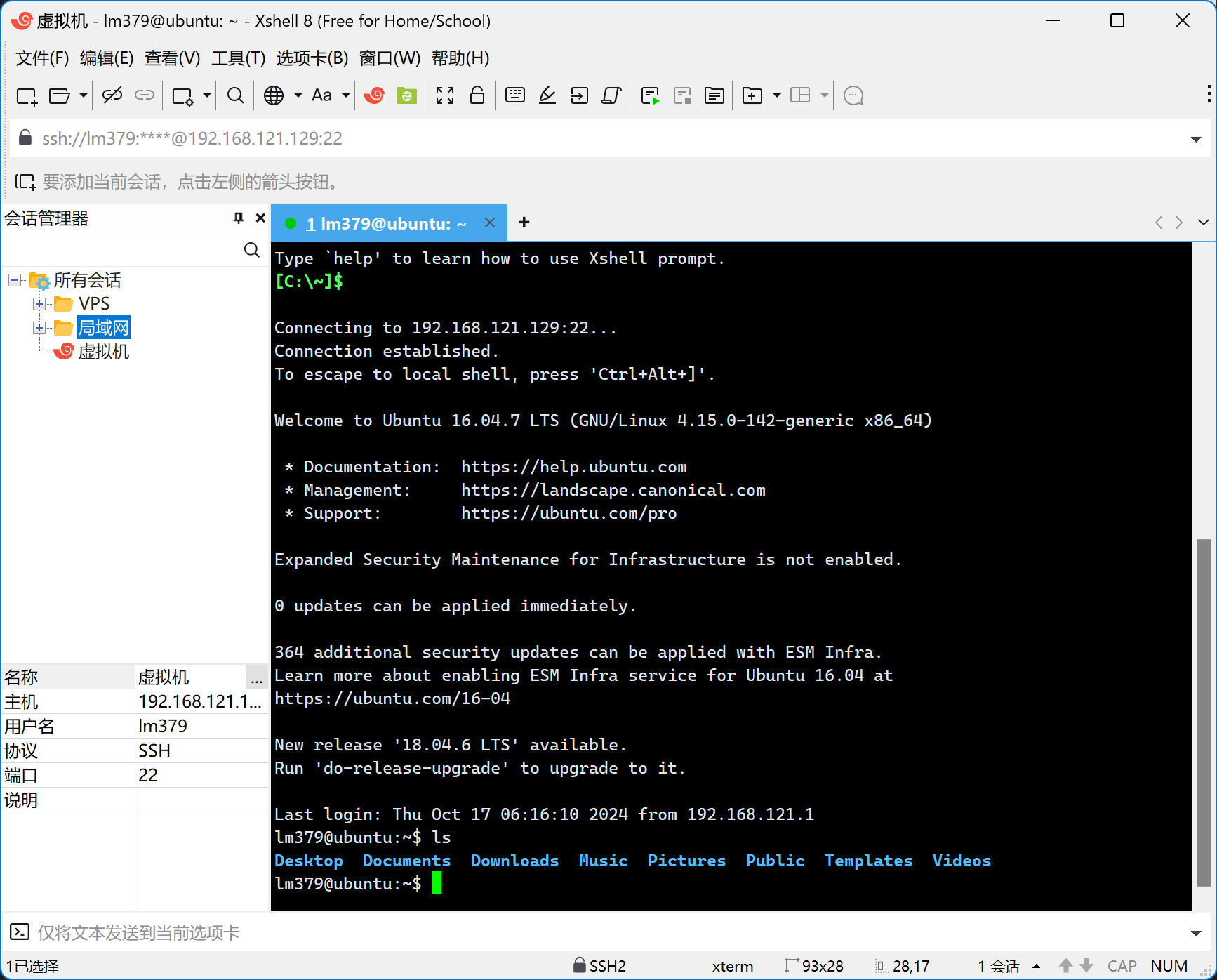
配置Java环境
这里不通过apt直接安装,而是手动下载jdk进行安装
实测通过apt安装的JDK会存在莫名其妙的问题
下面通过华为云JDK镜像进行下载,虽然这个网站已经很久没有更新了,不过我下载的是JDK1.8,这里面有
我选择的是JDK-8u202版本,Linux系统下载图中这个就行
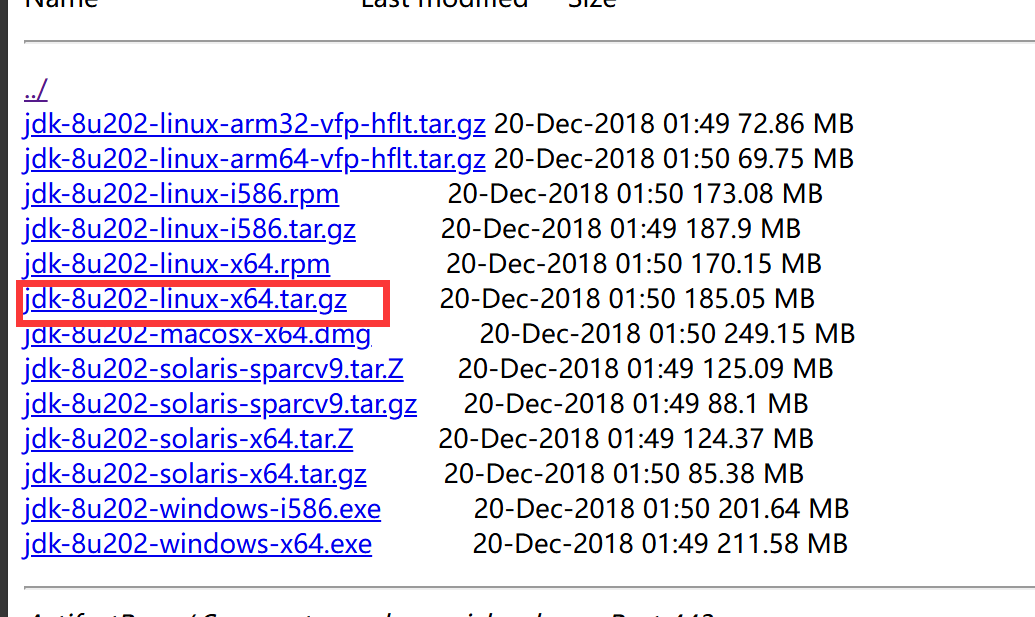
下载完成后通过SFTP工具(上面的XFTP)传到虚拟机内,也可以命令行下载
1 | cd ~/ |
然后创建一个文件夹用来存放Java环境,并解压JVM文件
1 | sudo mkdir /usr/lib/jvm |
并通过如下命令修改环境变量
1 | sudo nano ~/.bashrc |
定位到文件末尾
小技巧: nano编辑器中快速定位文件末尾快捷键 :先
Ctrl+W再Ctrl+V
在末尾输入如下配置
1 | export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_202 # 注意这一行为JDK解压后的目录,不同的JDK版本不同 |
然后通过快捷键 Ctrl+O回车保存, Ctrl+X退出nano编辑器
通过如下命令使刚才修改的配置生效
1 | source ~/.bashrc |
并通过命令 java -version 验证JDK是否配置成功,如果成功则会输出如下信息
1 | lm379@ubuntu:~$ java -version |
安装并初始化Hadoop
安装
下面以中科大镜像 为例,也可以去其他镜像站比如腾讯云镜像下载
可以先在主机下载,通过XFTP传到主机,不过我一般习惯直接通过wget
以3.4.0版本为例
1 | cd ~ |
通过如下命令检查Hadoop是否安装成功,如果成功会输出版本信息
1 | cd /usr/local/hadoop |
输出的版本信息示例
1 | hadoop@ubuntu:/usr/local/hadoop$ ./bin/hadoop version |
初始化
初始化之前需要先修改两个配置文件: core-site.xml 和 hdfs-site.xml
这两个文件位于目录 /usr/local/hadoop/etc/hadoop 下
这句话写给新手:建议使用nano vim之类的编辑器,通过终端输入,不要一个一个傻傻的敲
如果你实在不会nano或者vim,也可以用VSCode的Remote SSH组件,直接在宿主机内用VSCode编辑
两个文件的具体配置如下
core-site.xml
1 | <configuration> |
hdfs-site.xml
1 | <configuration> |
修改完成后,开始执行初始化
1 | cd /usr/local/hadoop |
然后可以看到如下的输出,其中包含 successfully formatted 说明初始化完成
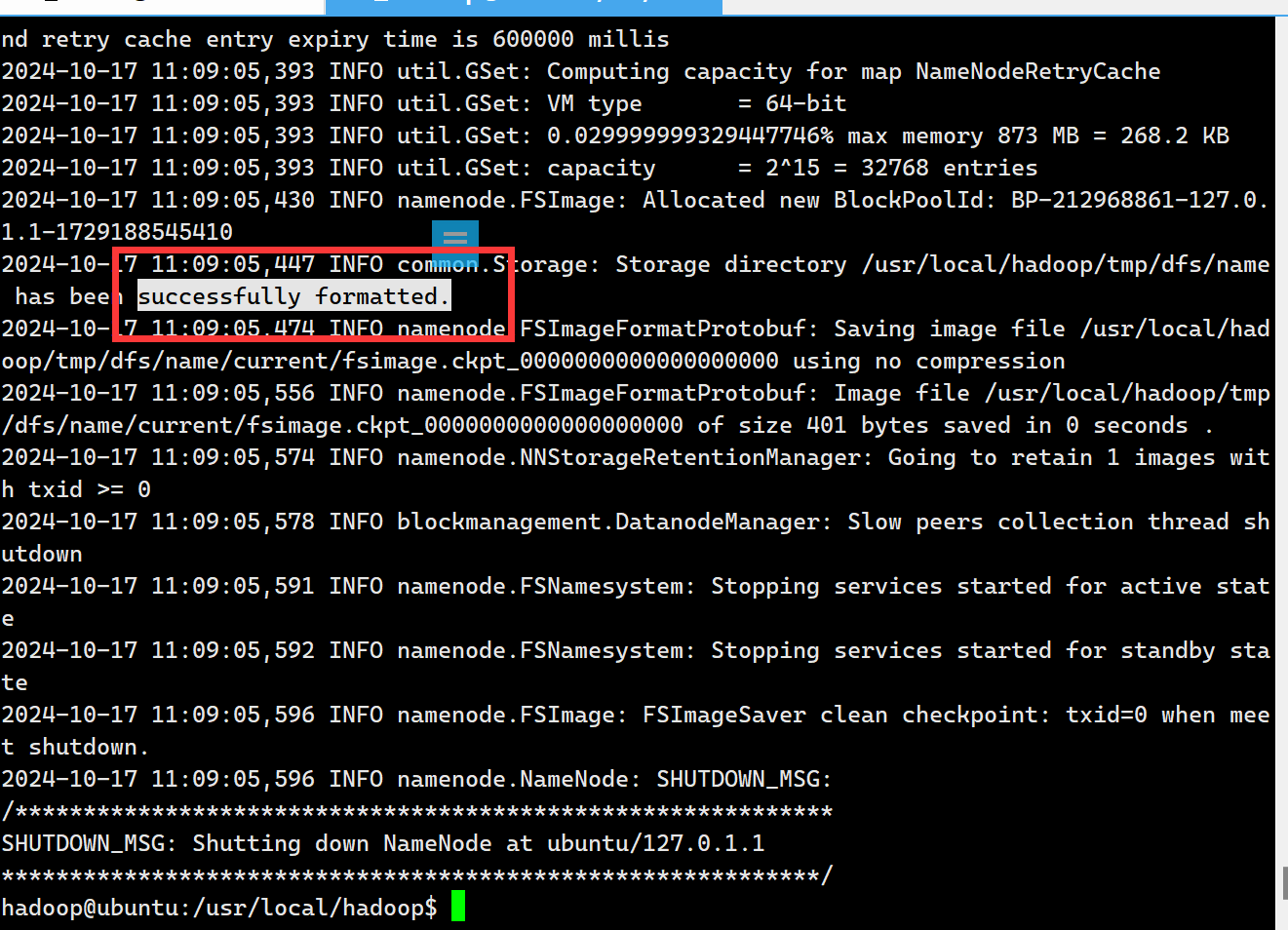
初始化成功后就可以开始运行了
执行
1 | ./sbin/start-dfs.sh |